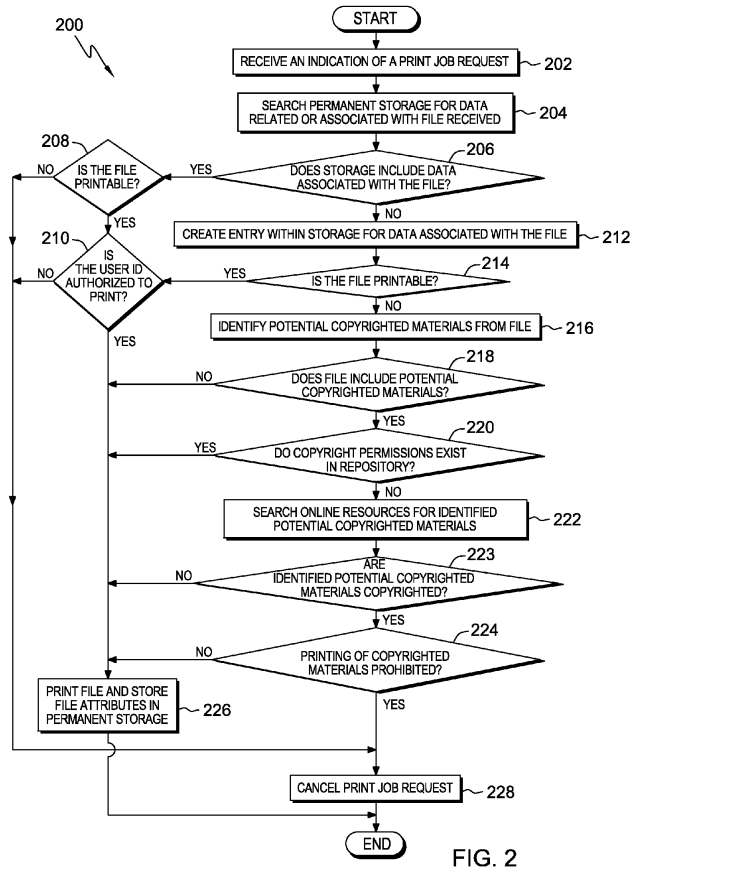
According to the patent titled “Copyright Infringement Prevention,” main goal is to ‘restrict’ the functionality of printers, so they only process jobs when the person who’s printing them has permission to do so.
The technology works by parsing content for potential copyrighted material. It will not allow the printer to copy or print the job, if such material is found. “The computer, in response to identifying any text, images, or formatting indicative of potential copyrighted material, identifies potential copyrighted material within the file.” “The computer determines whether the file may be printed based, at least in part, on the identified potential copyrighted material,” the patent description adds. The patent describes various variations on this approach, and IBM notes that ISBN numbers, United States Copyright Office records, and other public resources could be used to define the copyright status of a work. For instance, it may also include a feature that offers users with “options to acquire permissions” to print or copy something. If any of the text, images or formatting is prohibited, the print job simply would not go ahead. The printer can also be used to scan through large amounts of text and conduct plagiarism checks.